Object detection (or rather, recognition) is one of the fundamental problems in computer vision and a lot of techniques have come up to solve it. Invariably all of them employ machine learning, because the computer has to first 'learn' that a particular bunch of pixels with particular properties is called a 'book', remember that information, and use it in future to say whether the query image has a book or not.
You should know about two terms before reading on. Training images are the images which the detector uses to learn information. Query images are the images from which the detector, after learning, is supposed to detect object(s).
Generally, our aim in such experiments would be to achieve robust object recognition even when the object in a query image is at a different size or angle than the training images. These are called scale in-variance and rotation in-variance respectively, something like this -
 |
| Scale and Rotation in-variance in object detection |
Remembering all the pixels in the image of a book and then looking for them in query images is obviously a naive idea, since query images may have the same book at a different scale. This technique, know as template matching is also fooled by occlusions of other objects over the book in the query image. However, template matching is rotation invariant, and certain techniques like employing an image scaling pyramid can also make it pretty much scale invariant.
That being said, template matching (because of the sheer volume of pixels that it processes) is slow and requires a lot of memory.
The standard method in OpenCV to detect objects is to use its ready-made objdetect module, which uses the method of Haar cascade classifiers proposed by Viola and Jones. After training with thousands of positive and negative images for days on end, you can get a classifier file which contains all the training information. Load it into your program and you are ready to detect your object. This method is well-tested, works fast, and is scale invariant. But it is not rotation invariant and as I said, requires long training.

 |
| Rotation variance of the OpenCV objdetect module |
But, to quote Gandalf, oft hope shall be born when all is forlorn. There is a method for object detection that is scale and rotation invariant, robust, fast and most importantly, can work with a single training image! Speeded-Up Robust Features, SURF in short. A discussion of all the intricacies of its working is quite out of the scope of this article, but interested people can find the paper on it here.
A short description, though. What SURF does is -
- Find interest points in the image using Hessian matrices
- Determine the orientation of these points
- Use basic Haar wavelets in a suitably oriented square region around the interest points to find intensity gradients in the X and Y directions. As the square region is divided into 16 squares for this, and each such sub-square yields 4 features, the SURF descriptor for every interest point is 64 dimensional.
- For a description of the 4 features, please refer the paper - they are basically sums of gradient changes.
What I am going to show you here is how to implement SURF in a real-time application using OpenCV, and a strategy for matching descriptors.
Matching Strategy
A 64 dimensional descriptor for every key point sounds cool, but is actually useless without a method of deciding whether a query descriptor matches a training descriptor or not. For matching, we use the K nearest neighbour search. A KNN search basically computes the 'distance' between a query descriptor and all of the training descriptors, and returns the K pairs with lowest distance. Here we will keep K=2.
Hence we now have 2 pairs of matches for each query descriptor. So basically the KNN search gave us 2 matches to every query descriptor. What is important is how we decide which of all these matches are 'good matches' after all. The strategy we employ is (remember that each match has a 'distance' associated with it) -
For every query descriptor,
if distance(match1) < 0.8 * distance(match2), match1 is a good match
otherwise discard both match1 and match2 as false matches.
Real-time implementation
- Take an image of the object you want to detect and extract SURF descriptors for it. It is important for this image to contain only the object and to be free from any harsh lighting.
- Now do the same for every frame coming from your camera.
- Employ the matching strategy to match descriptors from every frame with the descriptors of the object and find out the 'good matches'.
- Create a window with the object image on one side and the video playing on the other side. Draw good matches between the two.
- To get a bounding box around a detected object, using the good matches, find a homography that transforms points from the object image to the video frame. Using this homography, transform the 4 corners of the object image. Consider these 4 transformed points as vertices and draw a box in the video frame.
The most important part is the matching strategy. SURF (as the name claims) is fast enough for all of this to be done for every frame coming from your camera. You can get something like this -
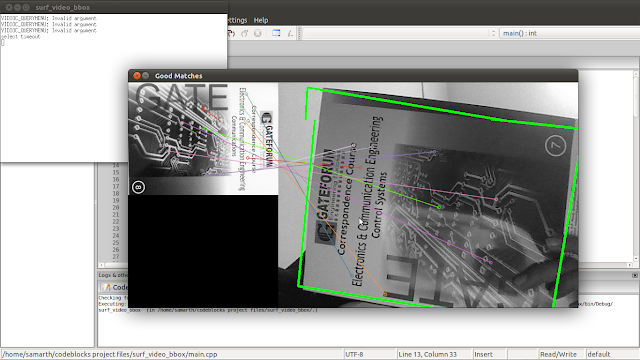
I removed the input image and matching lines, added a line to show the center of the bounding rectangle, and made the video at the top of the page.
Code
The OpenCV code here does real-time object detection in OpenCV using SURF, and also draws a bounding box around the detected object if 4 or more good matches are found.
Further Work
OpenCV also gives an option to 'train' your descriptor matcher using 5-10 images. It should be fun to see if training actually improves robustness.